

Fix pathway reliability—before bottlenecks and handoffs quietly drive delays, drop-offs, and rework.
You own clinical standards and care quality. We protect pathway reliability under real capacity and flow constraints.
We turn pathways (guidelines, SOPs, protocols) into explicit, reviewable models—so bottlenecks, drop-offs, and variability are visible before rollout.
Not a consulting slide deck. Not generic analytics. We stress-test pathways against operational reality.
~1 business day • no PHI required • we test decision logic, not outcomes
Most pathway failures aren’t clinical. They’re operational.
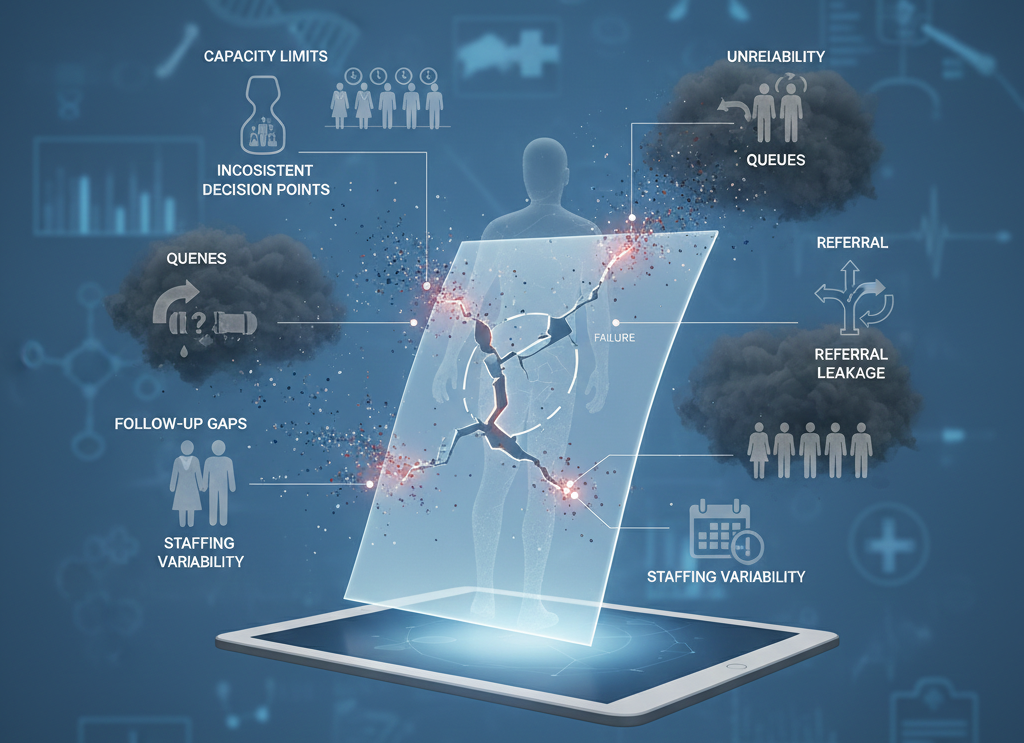
Pathways often look clean on paper, but break in practice at the handoffs: capacity limits, queues, inconsistent decision points, referral leakage, follow-up gaps, and staffing variability.
When that happens, you don’t just get slower care—you get unreliable execution at scale, which drives avoidable delays, rework, and outcome variance.
If you don’t fix this (cost bullets)
- Bottlenecks grow invisibly until length-of-stay, throughput, or access metrics deteriorate.
- Drop-offs at handoffs create missed follow-up, duplicated work, and avoidable escalations.
- Teams apply the “same pathway” differently across shifts and sites → inconsistency and equity risk.
- Changes are rolled out based on intuition—then you discover failure modes at scale.
What you buy: a pathway that is testable before rollout
Pathway Model (explicit operational logic map)
The pathway expressed as decision points, handoffs, capacity constraints, and timing.
Bottleneck & Drop-off Map
Where queues form, where patients leak, and which step breaks first.
Intervention Scenario Pack
What-if tests: staffing, scheduling, triage rules, referral routing, follow-up cadence.
Artifacts are inspectable (LaTeX/PDF), versioned, and reviewable—not slide decks or black-box outputs.
Audit tiers (pick the depth you need)
Close to rollout? Pick the depth of reliability check you need.
+ Care Pathway Reliability Check (first-break detection)
+ Bottleneck & Drop-off Mapping (where rollout fails first)
Best for:
When you’re about to roll out a pathway change and need a fast, decision-grade view of where execution will break first—before operational reality forces mid-rollout fixes.
Outputs:
- Pathway Fragility Register (MRR) — lite, 1-page artifact
- Bottleneck & Drop-off Snapshot — top failure points + “fix-first” actions (what to change before rollout)
Scope:
First-break analysis across handoffs, capacity pinch points, and drop-off risk—focused on the minimum changes that materially improve reliability.
Typical turnaround:
Fast (days)
Best when you need:
A clean “go / don’t go / fix-first” view ahead of a committee meeting, rollout decision, or operational change window.
+ Tier A
+ Intervention Scenario Pack (what-ifs: staffing, scheduling, routing, follow-up cadence)
+ Measurement Decision Design (included when measurement choice is decision-critical)
Best for:
When reliability matters more than elegance: you need the pathway to hold under real capacity and flow constraints, not just in the policy document—and you need rollout confidence under real-world load.
Outputs:
- Pathway Fragility Register (MRR) (full)
- Pathway Logic Map (same artifact family—deeper view, not a different thing)
- Operational Decision Memo (committee / leadership review ready)
- Scenario Pack (Operational Stress Tests) — the minimal set of what-ifs that actually change the rollout decision
Includes (standard scenario stress tests):
- Capacity & queue pressure (where flow collapses under realistic demand)
- Handoff leakage / drop-offs (where patients miss steps, follow-up breaks, referrals fail)
- Variation across shifts/sites (inconsistent decision points and execution drift)
Typical turnaround:
1–2 weeks
Best when you need:
You want to roll out with confidence—because the bottlenecks, leakage points, and variance sensitivities are explicit and stress-tested.
+ Tier B
+ Mid-Course Adjustment Decision (pre-plan: least-disruptive fixes without breaking interpretability)
+ Transferability & Scaling Check (new sites/service lines)
+ Optional: Reusable pathway asset (documented I/O + scenario engine; code only if needed)
Best for:
High-exposure rollouts (multi-site deployment, high-volume service lines, externally reported metrics, or major operational investment at risk) where the real downside is not “no improvement”—it’s unreliable execution that only appears after scale.
Outputs:
- Full Pathway Logic Map + Architecture + Scenario Pack (audit-grade)
- “What changes conviction” thresholds (what conditions would actually flip the decision)
- Governance-ready appendix (traceable decision points, rules, and operational dependencies)
- Optional reusable asset (documented I/O + scenario engine; code only if needed)
Includes:
Expanded scenario coverage + an audit trail suitable for leadership, governance committees, and cross-site standardization.
Typical turnaround:
Project-based
Best when you need:
The downside isn’t being wrong—it’s becoming unreliable under capacity pressure and operational variance.
Scope discipline: Stage-0 and audits test decision logic—not outcomes.
What decision are you facing right now?
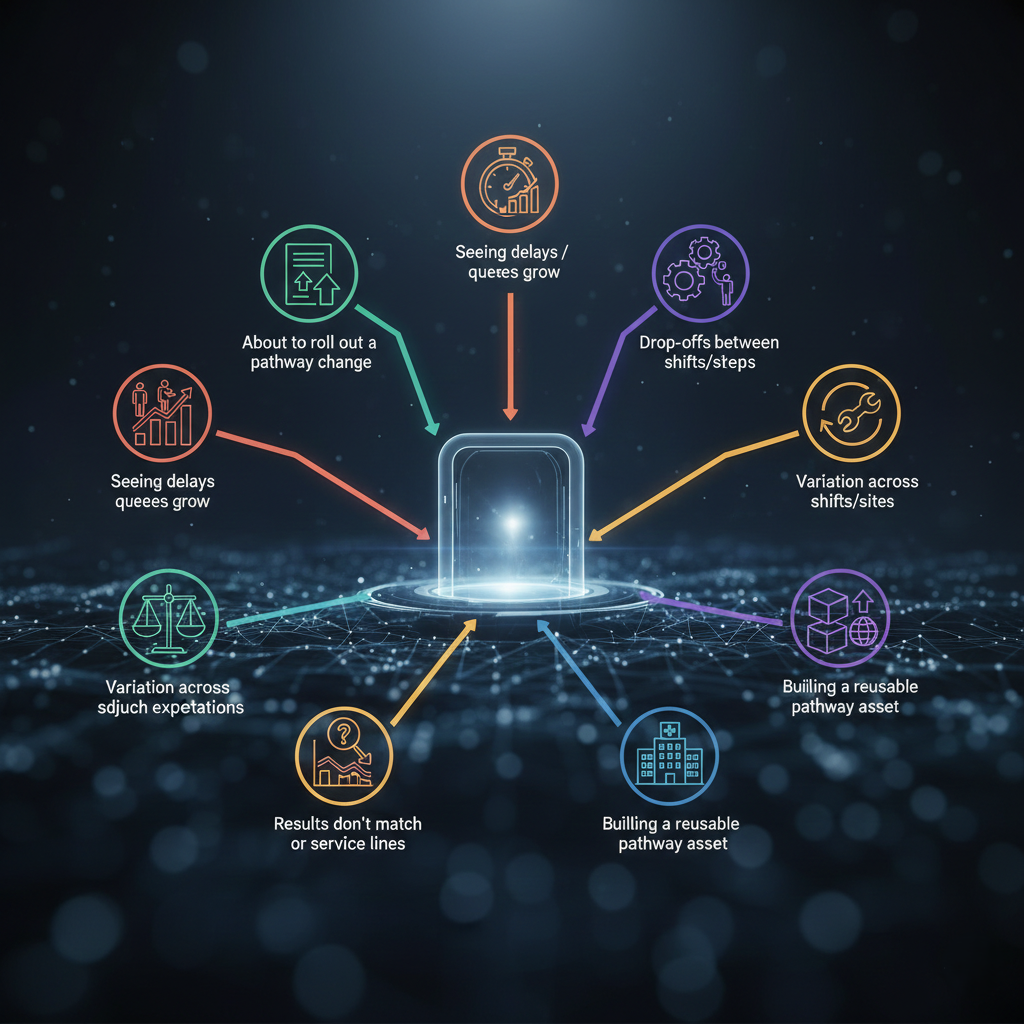
Pick the gate you’re at today:
Modules (same library, packaged for pathway reality)
- Design • Review • Mid-Study • Post-Readout • Asset
Phase A — Design (before rollout)
Hospital question:
Where does the pathway fail between steps, and why?
If you don’t do it:
you roll out change and discover bottlenecks/drop-offs at scale.
You get:
pathway model + bottleneck map + what-if interventions.
Hospital question:
What adjustment reduces risk without breaking interpretability of your metrics?
If you don’t do it:
you “fix” under pressure and can’t interpret whether the pathway helped.
You get:
constrained what-ifs + lowest-disruption adjustments + rationale memo.
Guardrail
We don’t replace clinical governance—scenario transparency only.
Hospital question:
What breaks first once the pathway meets real staffing and variability?
If you don’t do it:
failure modes show up after rollout—when changing is politically and operationally expensive.
You get:
first-break scan + fragility register + minimum fix set.
Hospital question:
Will this pathway transfer to another site/service line? What breaks?
If you don’t do it:
a pathway “works here” but fails elsewhere due to context differences.
You get:
transfer map + adjustment scenarios + scaling notes.
Hospital question:
Do we have enough signal to detect improvement under real-world variance?
If you don’t do it:
you invest in rollout without being able to tell if it helped.
You get:
detectability under drift + variance/missingness scenarios.
Not sure which block fits your situation?
Stage-0 helps you identify which decision risks actually matter before you invest further. You get a short written verdict — modelable as-is, modelable with changes, or not a fit right now — plus the lowest-effort next step.
Phase B — Review (committee / stakeholder scrutiny)
Hospital question:
Can we defend the pathway logic to governance committees and stakeholders?
If you don’t do it:
you face delays, scope creep, and endless debates because logic isn’t explicit.
You get:
defensibility pack + clear decision rules + governance-ready rationale.
Phase D — Post-Readout (after deployment evaluation)
Hospital question:
No improvement—because the pathway failed, or because execution drifted?
If you don’t do it:
you abandon a viable pathway or double-down on the wrong change.
You get:
divergence map + next-step options + targeted tests.
Hospital question:
Would this improvement hold if repeated across shifts or sites?
If you don’t do it:
your “success” is fragile and won’t generalize.
You get:
robustness checks + sensitivity notes + reproducible evaluation logic.
Hospital question:
What unmeasured operational variable is driving variance?
If you don’t do it:
you keep treating symptoms instead of the bottleneck cause.
You get:
candidate confounders + testable next-step plan.
Phase E — Asset (reuse/standardization)
Hospital question:
Can this pathway logic be reused and taught—or is it tribal knowledge?
If you don’t do it:
every site rebuilds the pathway differently and drift becomes permanent.
You get:
versioned package + assumptions log + standardization structure.
Inspect our math
Public, versioned artifacts—reviewable by peers.
De-identified examples on Zenodo and accompanying GitHub repos. Outputs are delivered in research-grade formats (LaTeX/PDF) suitable for citation and review—not marketing decks.
Enter Stage-0 (Pathway Intake)
Stage-0 is the first gate in our process. We review pathway logic and constraints only—no outcome optimization.
You’ll get a short written verdict in ~1 business day: modelable as-is, modelable with changes, or not a fit right now, plus the lowest-effort next step.
Form fields (minimal):
- Pathway type (ED, oncology, stroke, sepsis, peri-op, chronic care, etc.)
- Where it breaks (bottlenecks / drop-offs / variation / capacity)
- Constraints (staffing, capacity, scheduling, SLA targets)

No PHI required for Stage-0.